Yolov6가 출시된지 1달이 되었다. Yolov6는 특이하게도 Yolov7보다 늦게 출시되었다. Yolov6이 먼저 이름을 선점하고 github에서 작업을 시작하여 건너뛰고 Yolov7로 출시한 것 같다.
Yolov6는 여러 방법을 이용하여 알고리즘의 효율을 높이고, 특히 시스템에 탑재하기 위한 Quantization과 distillation 방식도 일부 도입하여 성능을 높혔다. Quantization 유/무에 따라 성능 변화가 거의 없다는 점이 인상적이다. 하지만 결과가 S모델만 있다는 것은 조금 아쉽다.
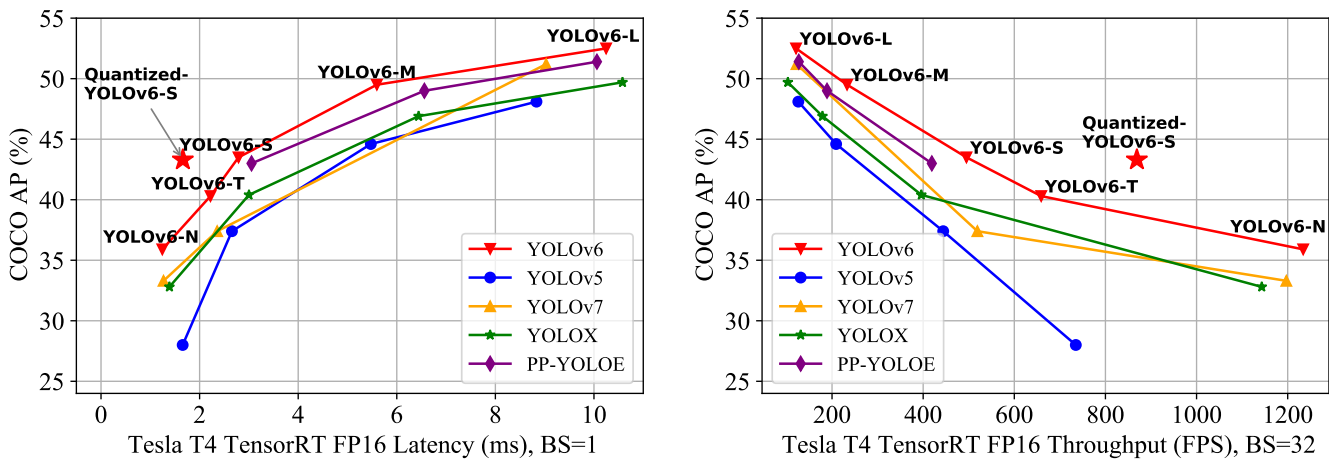
v7이 출시되고 v6가 출시되었기 때문에 비교표에 v7이 있다. 시스템에 탑재하기 위한 알고리즘을 주창해왔기 때문에 Quantization 결과도 있다. 기존 결과보다 상당히 향상된 것을 볼 수 있다.
전체 네트워크 구조는 다음과 같다.
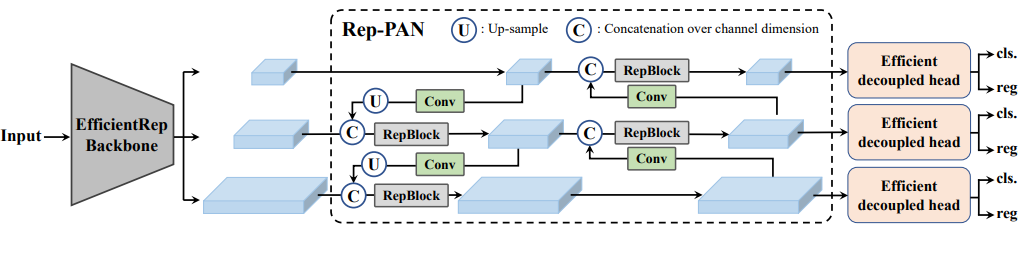
백본은 EfficientRep Backbone이 사용되었다. Neck 부분은 Rep-PAN이 사용되었다. head는 Efficient decoupled head가 사용되었다.
- 먼저 네트워크 구조에서 가장 핵심이 되는 기여는 CSPstackRep Block이다. CSPstackRep Block은 CSP(cross stage partial) + RepVGG 방식이다. 이 방식은 backbone에 사용된다.
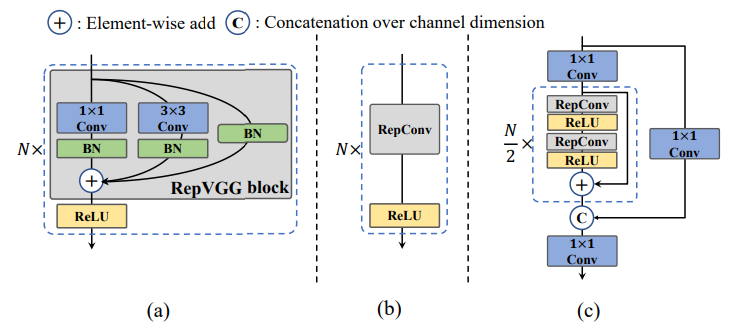
먼저 (a)에서 보여주는 것은 기존의 RepVGG이다. 거기에 ReLU를 넣어 RepBlock이라 명명한다. 이를 inference할 때에는 RepVGG에서 한 것처럼 RepConv로 변환되어 계산량을 줄인다 (b). (c)에서는 이렇게 만들어진 RepBlock을 사용하여 CSPstageRep Block을 만든 모습이다.
CSP는 DenseNet에서 시작된 Denseblock 방식의 업그레이드 버전이다. Denseblock의 첫 convolution을 모든 feature map에 대하여 하는 반면에, CSP는 처음 단계에서 일부(반 혹은 1/3, 2/3)만 convolution하여 concatenation를 하는 방식이다. 이로 인해 성능은 높이면서 계산량은 많이 줄었다. 이를 비슷하게 적용하기 위해 위 그림 (c)에서 1x1 Conv를 사용하여 CSP 처럼 부분적으로 convolution 후 concatenation해준다.
- Neck은 그림 1에서 보여지는게 전부이다. 중간에 RepBlock을 넣어서 PAN을 진행하였다.
- Head는 hybrid-channel 전략을 사용하였다. classification과 localiazation을 서로 decouple하여 학습하여 정확도를 높혔다. 3x3 convolution이 2개가 아닌 1개로 하고 width를 전체 구조에 맞게 스케일 조정을 하여 효율적으로 구동하게 하였다.
- Anchor-free 방식을 채택하였다. 그 중 anchor point-based 방식을 채택하였다. anchor point-based 방식 anchor point로부터 위,아래, 왼,오른쪽의 길이를 예측하는 방식이다.
- Label assignment는 SimOTA와 TAL중 TAL을 선택하였다. OTA는 최적화 기법을 사용하여 곂쳐진 물체에 대하여 잘 분별할 수 있도록 도와주는 알고리즘이다. 이를 간단히 적용한게 SimOTA이다. TAL은 TOOD논문의 일부이다. TOOD는 classification 점수와 예특 box를 통합하였다. 그로 인하여 box가 틀어지는 것은 많이 보완했다.
- Loss
classification loss는 VFL(VariFocal Loss)을 사용했다.
box regression loss는 큰 모델에는 GIoU, 작은 모델에는 SIoU를 사용했다.
Probability Loss로 DFL (Distribution Focal Loss)를 M/L 모델을 위해 사용했다.
Object Loss는 FCOS를 사용했다. 별로 좋진 않았다.
- Self-distillation
KL-divergence를 이용한 Self-distillation을 진행하여 성능을 상승시켰다. Self인 이유는 pretrain된 모델을 이용하여 자신에게 학습을 가하였기 때문이다. DFL 덕분에 box loss에도 KL-divergence를 사용할 수 있었다. 수식은 아래와 같다.
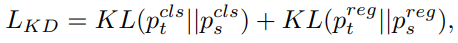
또한 Self-distillation Loss를 Detect loss와 결합하면서 비중을 조절하여 학습을 진행한다.
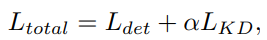
- Quantization
PTQ (Post-train Quant)와 QAT(Quant aware train) 방식이 있다. PTQ는 실패하였지만 QAT는 상당한 성능향상을 보였다.
- Re-parameterizing Optimizer for PTQ
Re-parameterizing Optimizer를 이용하여 PTQ를 진행하였다. Re-parameterizing Optimizer는 기존의 SGD 같은 범용적optimizer와 다르게 특정 reparameterization based model의 구조에 특화된 optimizer이다. 그로 인하여 가장 영향이 많이 미치는 layer를 뽑아낼 수 있다.
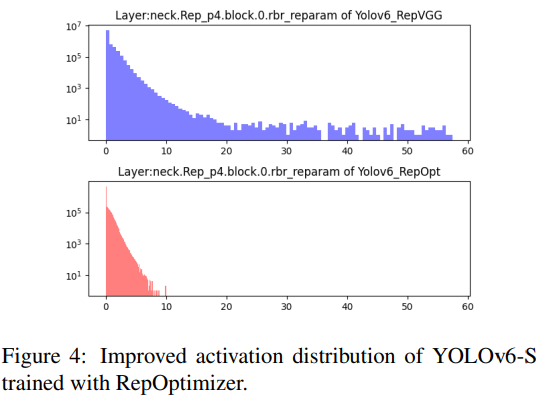
위 그림은 RepOptimzer를 이용하여 영향을 dominent하게 미치는 layer의 양이 줄어든 것을 볼 수 있다. 이런 정보를 활용하여 top-6 영향을 끼치는 layer를 선정하여 PTQ에 활용하였다. 그 결과는 아래와 같다.
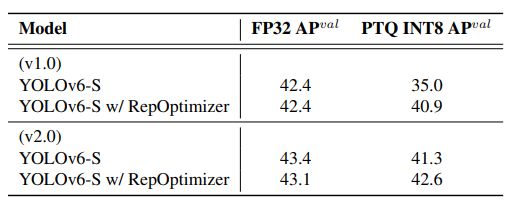
RepOptimizer를 이용하여 PTA를 적용했을 때 42.4 -> 40.9로 소폭만 줄어들었다.
- 이를 더욱 극복하기 위하여 QAT를 활용하였다. QAT는 channel wise self-distillation를 사용하였다. 아래와 같이 특정 feature map의 32bit, 8bit간 self-distillation을 진행한다.
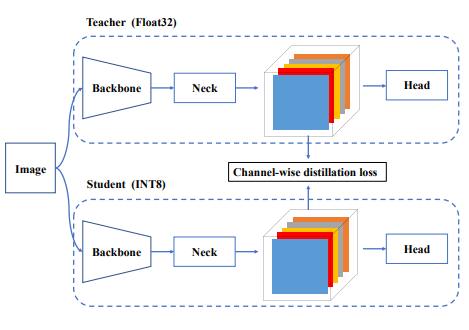
그 결과는 아래와 같이 매우 좋다. 하지만 RepOptimizer와 Partial QAT를 사용했을 때 결과가 가장 좋았다.

결론
CSPstageRep block사용과 Rep-PAN사용, 효율적인 head, Loss, label assignment, self-distillation 등을 활용하여 네트워크를 구성하여 성능을 높힘. Quantization의 양대 산맥인 PTQ, QAT를 모두 활용하여 거의 손해 없이 Quantization을 이루어냄.
'돈돈코딩' 카테고리의 다른 글
| 리눅스 터미널 쉘 명령어 for문과 if문을 함께 사용하기 전 알아야 할 것들 (0) | 2021.07.12 |
|---|---|
| [리눅스 터미널 명령어] find로 원하는 파일들을 이름을 기준으로 모두 한번에 복사해오기. (0) | 2021.07.08 |
| 리눅스 터미널에서 for문 돌리기 (다수의 파일 이름 일괄 변경) (0) | 2021.07.08 |
댓글